
Ever wondered how self-driving cars recognize pedestrians or how doctors identify tiny abnormalities in medical scans? Behind these breakthroughs are two technologies shaping the future of computer vision: Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs). But as problems get more complex, like analyzing massive satellite images or making sense of chaotic traffic scenes, can the tools we use, like Vision Transformers or CNNs, keep up?
CNNs have been the backbone of computer vision for decades. They break down images into small parts and process them step by step. Vision Transformers, however, are shaking things up. They take a completely different approach, simultaneously looking at the whole image to find patterns and relationships that CNNs might miss. This ability to handle complexity makes ViTs the rising star in the field.
In this article, we’ll see how these two technologies work, compare their strengths, and explore where each is used. Whether you are an AI engineer or just curious about how machines learn to see, this is your guide to understanding the future of computer vision. Ready to take a closer look?
The Origin Stories
Every superhero has an origin story, as do the technologies behind computer vision. CNNs are the veteran heroes. Seasoned and trusted, their journey began in the late 1980s when Yann LeCun created a CNN to recognize handwritten digits. It wasn’t flashy, but it got the job done. In 2012, CNN had its superhero moment with AlexNet. This model dominated the ImageNet competition and established them as go-to tools for object detection and facial recognition tasks.
In 2020, a new hero stepped into the world of computer vision: ViTs. Developed by Google researchers, their approach was bold. Inspired by Transformers, which are used in language models, ViTs introduced a new way of processing images.
Instead of analyzing small sections of an image, ViTs looked at the entire picture simultaneously. It allowed them to identify patterns and relationships across the whole image, making them ideal for tasks requiring a bigger-picture understanding, like studying satellite images or detecting fine details in complex scans.
ViTs are not just another tool. They represent a leap forward in how machines understand visual data. Their unique ability to handle complexity makes them a reliable tool in computer vision.
Getting to Know a Vision Transformer
ViT architecture introduces a unique way of analyzing images inspired by Transformers in natural language processing. Rather than analyzing parts of an image in isolation, ViTs divide the image into patches and process them together as a sequence. This design enables the model to understand the image holistically while preserving essential details.
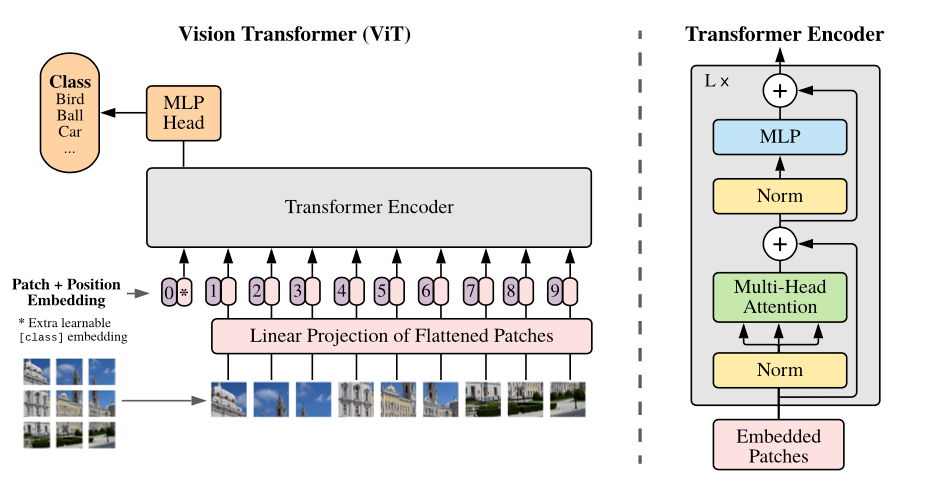
Let’s take a closer look at how ViTs are structured.
ViT works like a team solving a puzzle. It begins by dividing the image into small, fixed-size patches. Each patch is a puzzle piece, carrying part of the image’s information. The patches are then converted into numerical representations and prepared for processing.
Positional information is added to each patch to show where it belongs in the overall image. This ensures the model understands the relationship between patches and how they fit together.
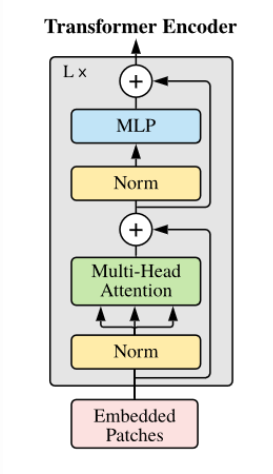
The Transformer encoder is where all the processing happens. Multi-Head Self-Attention enables each patch to interact with the others. It helps the model understand detailed features and broader connections across the image. Feed-forward networks refine the information further and sharpen the model’s overall understanding.
A special [CLS] token is added to the patch sequence. It gathers all the information shared in the Transformer layers. The final fully connected layer uses this token to predict the image’s class or label.
ViTs analyze the entire image and keep essential details intact. They are adequate for tasks requiring precision and context, such as analyzing satellite images or identifying patterns in medical scans.
Up Close and Personal with a CNN
CNNs work like an artist creating a masterpiece. It starts by zooming in on small image sections, using tools to identify simple features like edges, shapes, or textures. These tools, called convolutional layers, scan the image piece by piece to gather details.
After collecting these features, pooling layers act like the artist stepping back to get a better view. They simplify the information by focusing on the most critical details, reducing the complexity of the image and ensuring that key patterns remain intact. Activation functions help emphasize essential details, sharpening the model’s understanding.
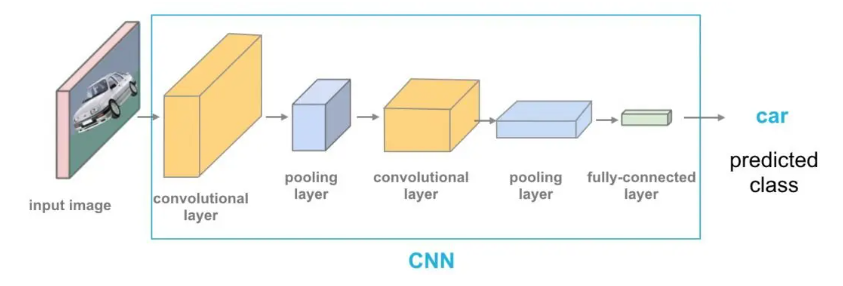
In the final stage, fully connected layers act like the artist finishing the painting. They combine all the collected features to understand the image. CNNs are well-suited for recognizing faces, identifying objects, or categorizing images. Their step-by-step process ensures accuracy and efficiency.
Vision Transformers or CNNs: Which is the Best
For years, CNNs have been loved resources in computer vision. They focus on fine details such as edges, shapes, and textures, which makes them a practical tool for object detection and facial recognition tasks. However, as tasks become more intricate, CNNs encounter difficulties.

ViTs approach the problem differently. They analyze the entire image at once, focusing on the relationships between all parts of the image. This method helps them understand both the finer details and the overall context. ViTs excel in tasks like analyzing satellite images or detecting subtle patterns in medical scans, where understanding the whole picture is just as important as identifying specific details.
Large datasets significantly enhance Vision Transformers’ performance. Their flexible architecture, inspired by Transformers in language models, easily adapts to complex tasks. CNNs, which rely on fixed filters and local operations, often struggle in these scenarios.
ViTs offer a more innovative and comprehensive way to analyze images. They combine attention to detail with understanding the bigger picture, representing a significant step forward in computer vision.
Applications of ViTs and CNNs
ViTs’ ability to analyze images allows them to excel in tasks that require global understanding. They can:
- Analyze satellite images to monitor urban development or environmental changes.
- Detects fine details in high-resolution medical scans for early diagnosis.
- Create and modify digital art using style transfer techniques.
- Process complex datasets like crowded scenes or astronomical imagery.
CNNs remain the trusted choice for traditional computer vision tasks. Their focus on local patterns ensures reliability and accuracy in many applications:
- Detects objects in images for autonomous vehicles and security systems.
- Power facial recognition is used in biometrics and smartphones.
- Assist doctors in identifying tumors or fractures in medical imaging.
- Classify images, such as recognizing animals or sorting handwritten digits.
Seeing the Big Picture: Where ViTs and CNNs Meet
Vision Transformers are changing the way machines understand images. They analyze the entire image simultaneously, which makes them ideal for complex tasks like satellite image analysis and high-resolution medical scans. ViTs combine accuracy with a complete view of the bigger picture and offer a fresh approach to solving visual problems.
That said, CNNs remain reliable for many traditional tasks. Their structured approach to detecting local patterns makes them perfect for object detection, facial recognition, and image classification applications.
The future of computer vision isn’t about vision transformers or CNNs replacing each other. It’s about finding the right tool for the task. Both CNNs and ViTs complement each other, each excelling in its domain. Together, they create a more versatile and capable future for how machines interpret the visual world. The next move is yours – where will you take computer vision?
This article was contributed to the Scribe of AI blog by Aakash R.
At Scribe of AI, we spend day in and day out creating content to push traffic to your AI company’s website and educate your audience on all things AI. This is a space for our writers to have a little creative freedom and show-off their personalities. If you would like to see what we do during our 9 to 5, please check out our services.