
Think about a situation where a chatbot gives you clear instructions about renewing a passport, yet the information turns out to be outdated because the government changed the rules last year.
The response looked confident and polished, but it was still wrong, and that makes the experience frustrating and unreliable. This happens because traditional large language models generate answers based only on what they learned during training and not on the latest verified information. They can sound smart while being factually incorrect, which is often referred to as hallucination.
These models also struggle with company-specific and domain-specific questions because that information is not included in their training data. In a world that depends on accurate answers for healthcare finance, education, customer support, and internal decision-making, the risk of wrong information becomes a major problem.
There is a need for AI systems that can reason well while also grounding their answers in real evidence. Retrieval-Augmented Generation, also called RAG, does exactly this by combining external information retrieval with language model generation.
It reduces hallucination and gives the model the ability to use verified knowledge before answering. In this blog, we will explore how RAG works, how it evolved, the different types of RAG where it is used in large real-world scenarios, and what innovations came after it.

What is RAG – The Core Concept
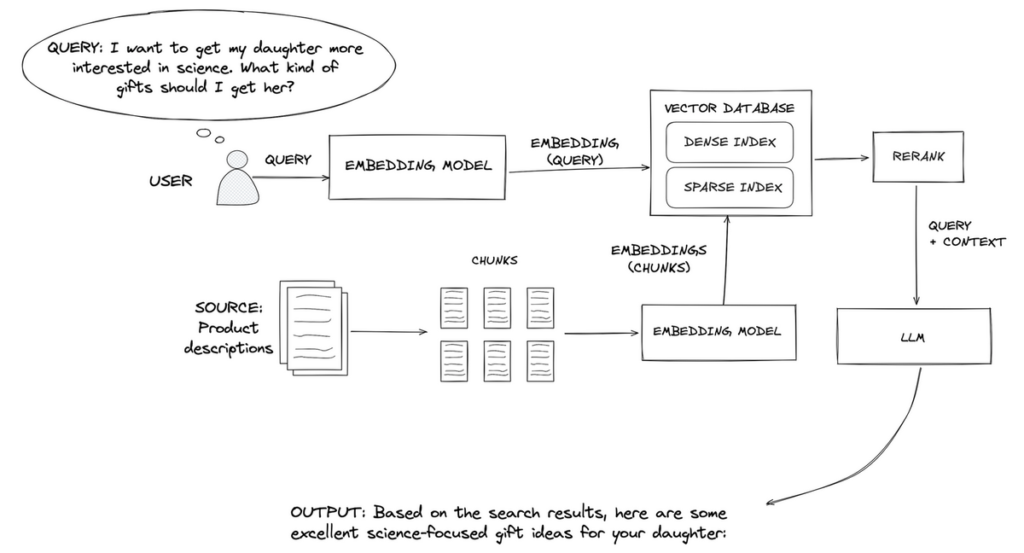
Retrieval-Augmented Generation is a technique that brings together two strengths in a single system, which are information retrieval and text generation. You can think of it as a student who is allowed to look up reference books before answering a question instead of relying only on memory.
When a user asks a question, RAG first searches for the most relevant documents from trusted sources such as internal knowledge bases, websites, research repositories, or private organizational datasets.
The language model then reads that information and produces an answer that is grounded in what it has retrieved. This allows the model to provide accurate responses even when the information was never part of its original training data.
A simple high-level flow works like this: a user submits a query, the system retrieves the most relevant documents, and the language model generates a final answer grounded in that evidence. This combination makes RAG powerful because it joins the fluency of language models with the reliability of factual knowledge systems.

For example, a healthcare assistant using RAG can refer to updated medical guidelines before giving advice, which keeps responses safe and trustworthy. RAG also works well for enterprises where staff need answers from policies, product manuals, or internal tickets that are not available publicly.
Once this core idea became popular, researchers and companies started creating more versions of RAG to solve different use cases and data challenges. This evolution led to the different types of RAG that exist today, and each version unlocks new possibilities.
Evolution of Retrieval-Augmented Generation
Here’s an overview of how RAG models have evolved:
- RAG V1 (2020–2022): Early Retrieval-Augmented Generation combined basic retrieval with generation. This period introduced vector databases, allowing models to search large document collections more efficiently.
- Advanced RAG (2023): The next wave added smarter techniques such as context ranking, chunking strategies, prompt engineering, and metadata filtering, which improved how models selected and organized information.
- RAG 2.0 / Modular RAG (2024): RAG systems became more flexible with the introduction of agent workflows, routing strategies, and multiple retriever components working together to handle different types of queries.
- Enterprise-Grade RAG (2025+): Modern RAG now supports multimodal retrieval, real-time data pipelines, and privacy-preserving features, making it suitable for large-scale enterprise environments.
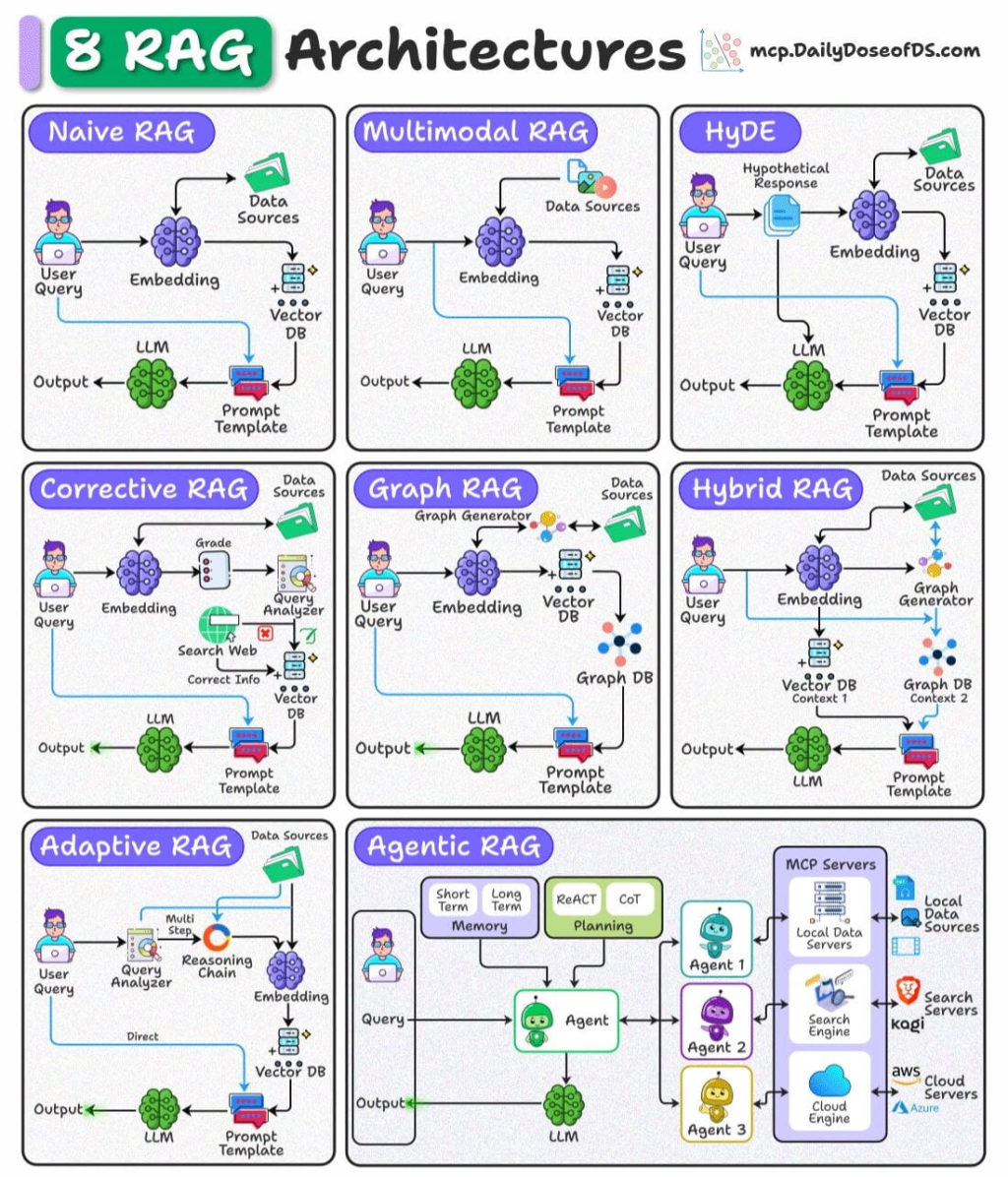
Types of RAG
Here’s a glimpse of the different types of RAG architectures:
- Basic RAG: Uses a single vector search to retrieve relevant text and then generates an answer. Best for simple tasks like FAQs, helpdesk responses, and basic knowledge lookup.
- Hybrid RAG: Combines vector search with keyword and semantic search to get more accurate matches. Useful in fields like legal, finance, and research where precision matters.
- Hierarchical RAG: Retrieves information in multiple stages, moving from broad context to specific details. Ideal for long documents, technical manuals, or entire books.
- Adaptive RAG: Dynamically switches between different retrieval sources based on the question. Often used in large enterprises where teams have separate knowledge bases.
- RAG with Agents: Adds task planning and tool usage on top of retrieval and generation. Helps with workflow automation, multi-step reasoning, and data analysis tasks.
- Real-Time RAG: Uses live APIs or streaming data instead of static documents. Useful for stock market analysis, logistics, and real-time monitoring.
Applications of Retrieval-Augmented Generation
Next, let’s discuss some of the common real-world use cases of RAG.
RAG in Healthcare
Retrieval-Augmented Generation is especially powerful in healthcare because clinicians often need fast access to verified information. RAG systems can search medical records, clinical guidelines, and research papers, then generate answers grounded in those sources.
For example, a doctor reviewing treatment options can ask for medication summaries supported by evidence rather than relying on generic model output. In another scenario, hospital staff can use RAG to surface relevant patient history during emergency care.
These systems reduce the risk of inaccurate responses because the model retrieves only approved medical content before generating suggestions. As a result, RAG supports safer clinical decision-making.
RAG for Financial Services
Financial institutions deal with complex reports, regulations, and fast-changing market conditions, which makes retrieval crucial. RAG can analyze regulatory documents, compliance rules, and risk reports, then generate concise and grounded summaries.
For instance, compliance teams can ask RAG to check whether a new policy aligns with existing regulations, supported by retrieved clauses. Analysts can also use RAG for portfolio risk assessment by combining live market data with historical trends.
Because RAG pulls from verified internal and external documents, it reduces the chance of hallucinations and speeds up research that normally takes hours. This makes financial workflows more dependable and efficient.
RAG in Legal
Legal work depends heavily on case law, statutes, and detailed documentation. RAG systems can retrieve relevant cases, highlight similar rulings, and draft structured arguments based on retrieved evidence.
For example, a lawyer preparing a motion can ask RAG to identify precedents that match a specific fact pattern. Paralegals can use it to summarize lengthy contracts or extract obligations and timelines.
Since RAG grounds its answers in actual legal texts rather than model guesses, it improves accuracy while saving significant research time. This creates a practical workflow where legal teams can move from information gathering to argument building much more quickly.
RAG for E-Commerce
In e-commerce, RAG can enhance product discovery and personalized shopping experiences. It retrieves product data, user preferences, and reviews, then generates tailored recommendations. For instance, a shopper can ask, “Show me running shoes for flat feet,” and RAG will pull relevant listings before generating a clear comparison.
Customer support chatbots also benefit because RAG retrieves policy documents, warranties, or instructions to answer questions accurately.
Merchants can use RAG to analyze customer behavior, summarize trends, and improve inventory planning. The combination of retrieval and generation creates smoother, more helpful shopping interactions.
RAG in Education
Education platforms generate large amounts of content, from textbooks to lecture notes to assessments. RAG can retrieve institution-specific material and generate personalized learning paths.
For example, a student struggling with calculus might receive custom explanations drawn from their own course materials. Instructors can use RAG to create quizzes, summaries, or lesson plans that align with existing curricula.
Universities can also build knowledge portals where students ask questions and receive grounded responses instead of generic answers. By using verified academic content, RAG supports more accurate learning assistance and scalable content creation.
RAG for Enterprise Search
Large organizations often store knowledge across many tools, folders, and teams, making information retrieval difficult. RAG provides one-shot access by retrieving content from documents, emails, wikis, and databases, then generating a unified answer.
For instance, an employee needing onboarding instructions can get a complete explanation grounded in HR files, IT documentation, and internal policies. Product teams can search engineering notes, requirements, and past experiments to avoid repeating work.
Because RAG combines retrieval with generation, workers get clear and contextual responses rather than long lists of documents. This improves both productivity and decision-making across the enterprise.
Real-World Applications of Retrieval-Augmented Generation
As Retrieval-Augmented Generation (RAG) has matured, it has moved from academic research into high-impact real-world deployments across industries, transforming how organizations access and leverage knowledge.
In financial services, JPMorgan Chase’s EVEE intelligent Q&A leverages RAG to allow call-center specialists to query internal documentation and receive precise answers drawn from policy manuals and procedures. This integration with internal knowledge bases has improved efficiency and accuracy in handling complex inquiries across fraud, claims, lending, and collections.
Similarly, in telecommunications and enterprise search, public sector innovators such as IIT Kanpur and the Uttar Pradesh Police have launched RAG-based information bots that allow officers and citizens to query over 1,000 police circulars and procedural guidelines in natural language, enhancing government service accessibility and transparency.
One of the most compelling scientific applications comes from NASA. Researchers at NASA’s Ames Research Center have developed NASA-GPT, a RAG-based system that retrieves highly relevant sections of technical reports and databases, such as the NASA Technical Reports Server (NTRS) and Jet Propulsion Laboratory archives, to ground generative responses in authoritative mission documentation.

Across sectors such as healthcare, finance, and legal, RAG systems are increasingly used for domain-specific question answering, compliance analysis, and decision support, enabling professionals to derive actionable insights from complex, up-to-date knowledge bases rather than static model training.
Challenges in Retrieval-Augmented Generation
Here are some of the key challenges organizations face when implementing Retrieval-Augmented Generation (RAG) systems:
- Balance: RAG systems must balance retrieval quality and generation quality. A strong retriever is not useful if the generator cannot use the context well. A strong generator is not reliable if the retrieved context is weak.
- Governance: Trust and governance remain major hurdles. Teams need clear control over sources, copyright rules, and audit trails so that every answer can be traced.
- Latency: Enterprise scale brings latency issues. Real-time RAG needs fast retrieval and low model load without driving cost beyond limits.
- Relevance: Context windows grow each year, yet overload still happens. Large context does not guarantee relevance. Systems must avoid pushing noise into the model.
- Stability: Continuous updates can break embeddings or create drift. Teams need stable refresh cycles so that knowledge stays fresh without harming accuracy.

Key takeaways
RAG has grown from a simple retrieval add-on into a core method that keeps AI grounded in real knowledge. It strengthens model accuracy, cuts errors, and unlocks real value across industries. RAG does not replace models; instead, it makes them relevant, reliable, and ready for real-world use.
This article was contributed to the Scribe of AI blog by Aarthy R.
At Scribe of AI, we spend day in and day out creating content to push traffic to your AI company’s website and educate your audience on all things AI. This is a space for our writers to have a little creative freedom and show off their personalities. If you would like to see what we do during our 9 to 5, please check out our services.